你可能见过人工智能生成图像,比如这四只柯基犬。

也许你也见过人工智能生成声音,比如这些柯基犬吠叫的声音:
如果我告诉你这两代人是完全相同的东西怎么办?亲自观看和聆听!
现在,当我说“它们是同一件事”时,您可能会对我的意思感到困惑。但不用担心;你很快就会明白!
2024年5月,密歇根大学的三名研究人员发表了一篇题为“有声音的图像:在单一画布上创作图像和声音”的论文。
在这篇文章中,我将解释
- 生成“有声音的图像”意味着什么,以及这与人类之前的工作有何联系
- 该模型如何在技术层面上工作,并以易于理解的方式呈现
- 为什么这篇论文挑战了我们对人工智能可以做什么和应该做什么的理解
要回答这个问题,我们需要了解两个术语:
- 波形
- 频谱图
在现实世界中,声音是通过振动物体产生声波(气压随时间变化)而产生的。当通过麦克风捕获声音或由数字合成器生成声音时,我们可以将该声波表示为波形:

该波形对于录制和播放音频很有用,但通常不会用于音乐分析或音频数据的机器学习。相反,使用了信息更丰富的信号表示形式,即频谱图。

声谱图告诉我们随着时间的推移,声音中哪些频率或多或少明显。然而,对于本文,需要注意的关键是频谱图是图像。至此,我们回到了原点。
当生成上面的柯基犬声音和图像时,人工智能会创建一种声音,当转换成声谱图时,它看起来像柯基犬。
这意味着该人工智能的输出同时是声音和图像。
即使您现在了解了有声音的图像的含义,您可能仍然想知道这怎么可能。人工智能如何知道哪种声音会产生所需的图像?毕竟,柯基犬声音的波形看起来一点也不像柯基犬。

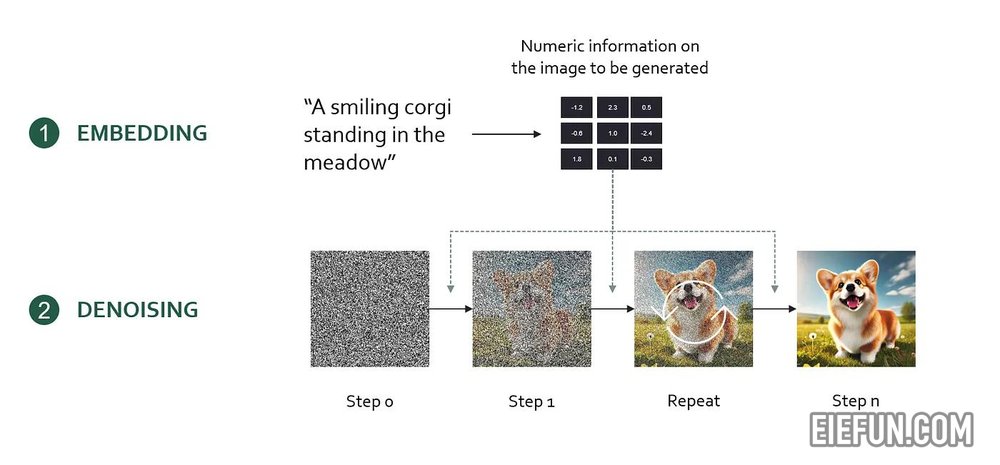
首先,我们需要了解一个基本概念:扩散模型。扩散模型是 DALL-E 3 或 Midjourney 等图像模型背后的技术。本质上,扩散模型将用户提示编码为数学表示(嵌入),然后使用该数学表示从随机噪声中逐步生成所需的输出图像。
这是使用扩散模型创建图像的工作流程
- 使用人工神经网络将提示编码为嵌入(一堆数字)
- 用白噪声(高斯噪声)初始化图像
- 逐步对图像进行去噪。基于提示嵌入,扩散模型确定最佳的小去噪步骤,使图像更接近提示描述。我们称之为去噪指令。
- 重复去噪步骤,直到生成无噪声的高质量图像
为了生成“有声音的图像”,研究人员使用了一种巧妙的技术,将两个扩散模型合并为一个。其中一种扩散模型是文本到图像模型(Stable Diffusion),另一种是文本到频谱图模型(Auffusion)。这些模型中的每一个都会接收自己的提示,该提示被编码到嵌入中并确定自己的去噪指令。
然而,多个不同的去噪指令是有问题的,因为模型需要决定如何对图像进行去噪。在论文中,作者通过对两个提示的去噪指令进行平均来解决这个问题,有效地指导模型对两个提示进行同等的优化。

在较高的层面上,您可以将其视为确保生成的图像能够同样良好地反映图像和音频提示。这样做的一个缺点是,输出始终是两者的混合,并且并非模型中发出的每个声音或图像看起来/听起来都很棒。这种固有的权衡极大地限制了模型的输出质量。
人工智能只是模仿人类智能吗?
人工智能通常被定义为模仿人类智能的计算机系统(例如 IMB、TechTarget、Coursera)。该定义非常适用于销售预测、图像分类和文本生成人工智能模型。然而,它有一个固有的限制:计算机系统只有执行人类历史上已经解决的任务,才能成为人工智能。
在现实世界中,存在大量(可能是无限的)可以通过智能解决的问题。虽然人类智能已经解决了其中一些问题,但大多数问题仍未解决。在这些未解决的问题中,有些是已知的(例如治愈癌症、量子计算、意识的本质),有些则是未知的。如果您的目标是解决这些未解决的问题,那么模仿人类智能似乎并不是最佳策略。
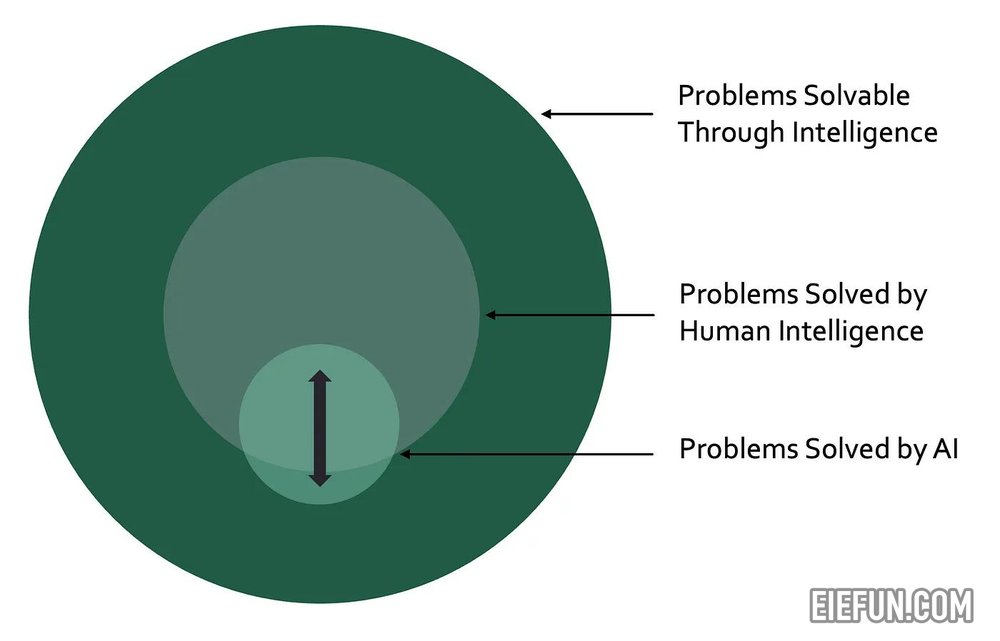
根据上述定义,如果计算机系统能够在不模仿人类智能的情况下发现癌症的治疗方法,则不会被视为人工智能。这显然是违反直觉且适得其反的。我无意就“唯一的定义”展开辩论。相反,我想强调人工智能不仅仅是人类智能的自动化工具。它有潜力解决我们甚至不知道存在的问题。
频谱图艺术可以用人类智慧生成吗?
在 Mixmag 上的一篇文章中,Becky Buckle 探讨了“艺术家将视觉效果隐藏在音乐波形中的历史”。人类频谱图艺术的一个令人印象深刻的例子是英国音乐家 Aphex Twin 的歌曲“ΔMᵢ⁻1=−α Σ Dᵢ[η][ Σ Fjᵢ[η−1]+Fextᵢ [η⁻1]]”。

另一个例子是加拿大音乐家 Venetian Snares 的专辑“Songs about my Cats”中的曲目“Look”。

虽然这两个例子都表明人类可以将图像编码为波形,但与“声音图像”的能力存在明显差异。
“声音图像”与人类频谱图艺术有何不同?
如果你听一下上面的人类声谱图艺术的例子,你会发现它们听起来像噪音。对于外星人的面孔来说,这可能是一个合适的音乐下划线。然而,听猫的例子,声音和频谱图图像之间似乎没有故意的关系。人类作曲家能够生成转换为频谱图后看起来像某种东西的波形。然而,据我所知,没有人能够根据预定义的标准生成声音和图像匹配的示例。
“有声音的图像”可以产生听起来像猫、看起来像猫的音频。它还可以产生听起来像宇宙飞船、看起来像海豚的音频。它能够在音频信号的声音和图像表示之间产生有意的关联。在这方面,人工智能展现出了非人类的智能。
“有声音的图像”没有用例。这就是让它变得美丽的原因
近年来,人工智能大多被描述为一种生产力工具,可以通过自动化提高经济产出。虽然大多数人都认为这在某种程度上是非常可取的,但其他人却感到这种对未来的看法受到了威胁。毕竟,如果人工智能继续夺走人类的工作,它最终可能会取代我们喜欢做的工作。因此,我们的生活可能会变得更有成效,但意义却更少。
“有声音的图像”与这个观点形成鲜明对比,是美丽的人工智能艺术的一个典型例子。这项工作不是由经济问题驱动的,而是由好奇心和创造力驱动的。这项技术不太可能有经济用途,尽管我们永远不应该说永远不会……
在我接触过的所有谈论人工智能的人中,艺术家往往对人工智能持最负面的态度。德国 GEMA 最近的一项研究证实了这一点,该研究显示,超过 60% 的音乐家“认为人工智能使用的风险大于其潜在机会”,而只有 11% 的人“认为机会大于风险”。
更多与本文类似的作品可以帮助艺术家了解人工智能有潜力为世界带来更多美丽的艺术,而这不必以牺牲人类创造者为代价。
图像和声音并不是人工智能第一个有潜力创造美丽艺术的用例。在本节中,我想展示一些其他方法,希望能够启发您并让您对人工智能有不同的思考。
恢复艺术

人工智能通过精确修复受损作品来帮助修复艺术,确保历史作品更长久。技术与创造力的结合使我们的艺术遗产为子孙后代留下了生命力。阅读更多 。
让画作活起来
人工智能可以将照片制作成动画,以创建具有自然动作和口型同步的逼真视频。这可以使历史人物或像蒙娜丽莎这样的艺术品动起来并说话(或说唱)。虽然这项技术在应用于历史肖像的深度赝品背景下肯定是危险的,但它可以创造有趣和/或有意义的艺术。阅读更多。
将单声道录音转为立体声
人工智能有潜力通过将单声道混音转换为立体声混音来增强旧录音。有一些经典的算法方法可以实现这一点,但人工智能有望使人工立体声混音听起来越来越真实。请阅读此处和此处的更多内容。
《Images that Sound》是我最喜欢的 2024 年论文之一。它使用先进的 AI 训练技术来实现纯粹的艺术成果,创造出一种新的视听艺术形式。最令人着迷的是,迄今为止,这种艺术形式已经超出了人类的能力范围。从这篇论文中我们可以了解到,人工智能不仅仅是一套模仿人类行为的自动化工具。相反,人工智能可以通过增强现有艺术或创造全新的作品和艺术形式来丰富我们生活的审美体验。我们才刚刚开始看到人工智能革命的开端,我迫不及待地想塑造和体验它的(艺术)后果。
我是一名音乐学家和数据科学家,分享我对人工智能和音乐当前主题的想法。以下是我之前与本文相关的一些工作:
- 2024 年预计将出现 3 项音乐 AI 突破:https://towardsdatascience.com/3-music-ai-breakthroughs-to-expect-in-2024-2d945ae6b5fd
- Meta 的人工智能如何根据参考旋律生成音乐:https://medium.com/towards-data-science/how-metas-ai-generates-music-based-on-a-reference-melody-de34acd783
- 人工智能音乐源分离:它是如何工作的以及为什么如此困难:https://medium.com/towards-data-science/ai-music-source-separation-how-it-works-and-why-it-is -如此困难-187852e54752
在 Medium 和 Linkedin 上找到我!
免责声明
本文内容(图片、文章)翻译/转载自国内外资讯/自媒体平台。文中内容不代表本站立场,如有侵权或其它,请联系 admin@eiefun.com,我们会第一时间配合删除。