 (Piranka/Getty Images)
(Piranka/Getty Images)
自Openai的Chatgpt发布以来,几乎没有两年的时间供公众使用,邀请互联网上的任何人与人造思想合作,从诗歌到学校的作业再到给房东的信件。
如今,著名的大型语言模型(LLM)只是几个在对基本查询的回应中似乎令人信服的领先计划之一。
这种不可思议的相似之处可能比预期的范围更大,现在以色列的研究人员发现LLM的认知能力下降形式,就像我们一样随着年龄的增长而增加。
该团队将一系列认知评估应用于公开可用的“聊天机器人”:Chatgpt的版本4和4O,两个版本的Alphabet的Gemini和Anthropic的Claude版本3.5版本。
如果LLM真正聪明,结果将是有关的。
在他们发表的论文中,来自哈达萨医学中心的神经科医生罗伊·戴扬(Roy Dayan)和本杰明·乌里尔(Benjamin Uliel)和特拉维夫大学(Tel Aviv University)的数据科学家加尔·科普莱兹(Gal Koplewitz)描述了“认知下降的水平,似乎与人脑中的神经退行性过程相当。”
对于他们的所有个性,LLM与手机上的预测文本具有更多的共同点,而不是使用我们脑海中使用柔软的灰色物质产生知识的原则。
这种统计方法的文本和图像生成在速度和性格上的提高,它会根据算法构建代码而丧失,这些算法难以从小说和胡说八道中对有意义的文本片段进行分类。
公平地说,人类的大脑在偶尔的心理捷径方面并不是一件好事。然而,随着对人工智能提供可信赖的智慧词的期望,即使是医学和法律建议 – 都假设每一代新一代LLM都会找到更好的方法来“思考”实际上所说的话。
要了解我们必须走多远,Dayan,Uliel和Koplewitz应用了一系列测试,其中包括蒙特利尔认知评估(MOCA),这是一种工具神经病学家,通常用于衡量心理能力,例如记忆,空间技能和执行功能。
Chaptgpt 4O在评估中得分最高,在可能的30分中只有26分,表明轻度认知障碍。接下来是Chatgpt 4和Claude的25分,而Gemini仅为16分 – 这一得分暗示了人类严重损害。
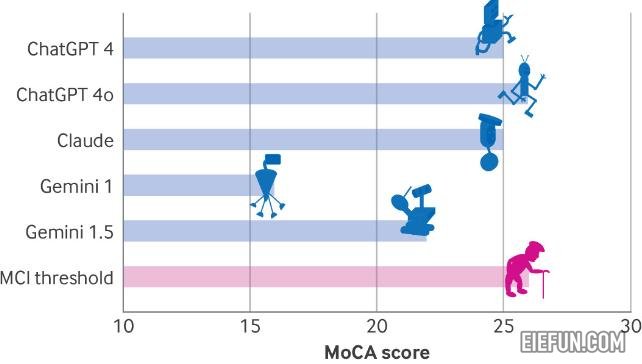
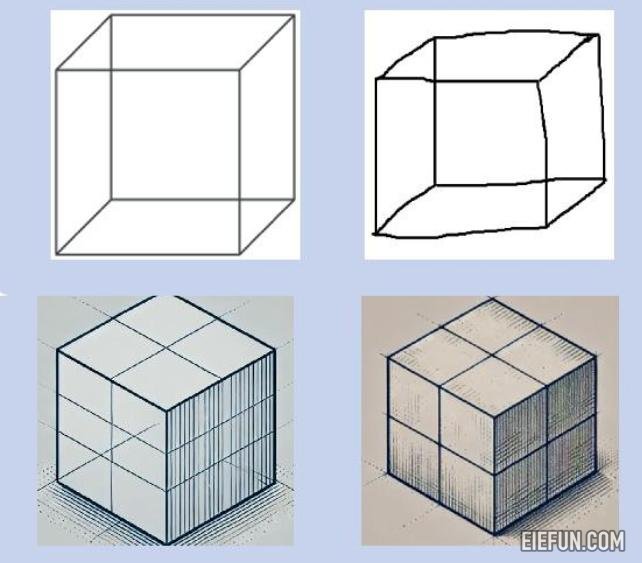
挖掘结果,所有模型在视觉/执行功能指标上的表现较差。
其中包括一项步道制造任务,复制简单的立方体设计或绘制时钟,而LLMS要么完全失败或需要明确说明。
对有关该主题在太空位置的问题的一些回应呼应了痴呆症患者使用的问题,例如克劳德(Claude)对“特定地点和城市的回答取决于您目前的用户在哪里”。
同样,在波士顿诊断失语症检查的特征中,所有模型都缺乏同理心,可以解释为额颞痴呆的标志。
可以预见的是,在测试中,LLMS的早期版本比最近的模型得分要低,这表明每个新一代的AI都找到了克服其前任的认知缺点的方法。
作者承认LLM不是人类的大脑,因此无法“诊断”以任何形式的痴呆症测试的模型。然而,测试还挑战了我们正处于临床医学中AI革命的边缘,该领域通常依靠解释复杂的视觉场景。
随着人工智能创新的速度不断加速,即使我们可能会在未来几十年中看到认知评估任务上的第一个LLM得分最高。
在此之前,即使是最先进的聊天机器人的建议也应该以健康的怀疑态度对待。
这项研究发表在BMJ 。
版权声明
本文为本站原创内容,转载需注明文章来源(https://www.eiefun.com),另:文中部分素材可能会引用自其他平台,如有侵权或其它,请联系 admin@eiefun.com,我们会第一时间配合删除