2022年,Stable Diffusion横空出世,成为AI行业从传统深度学习时代过渡至AIGC时代的标志模型,并为工业界和投资界注入了新的活力,让AI再次性感。本文介绍的Stable Diffusion XL是Stable Diffusion的优化版本,由Stability AI发布。比起Stable Diffusion,Stable Diffusion XL做了全方位的优化,Rocky相信,Stable Diffusion会是图像生成领域的“YOLO”,而Stable Diffusion XL那就是“YOLOv3”。 Stable Diffusion XL生成图片Rocky已经在知乎上持续撰写Stable Diffusion XL全方位的解析文章:https://zhuanlan.zhihu.com/p/643420260,内容包括模型结构,从0到1训练教程,从0到1搭建推理流程,最新SD资源汇总,相关插件工具使用等,后续会将全部内容都在公众号内分享!话不多说,在Rocky毫无保留的分享下,让我们开始学习吧!
Stable Diffusion XL生成图片Rocky已经在知乎上持续撰写Stable Diffusion XL全方位的解析文章:https://zhuanlan.zhihu.com/p/643420260,内容包括模型结构,从0到1训练教程,从0到1搭建推理流程,最新SD资源汇总,相关插件工具使用等,后续会将全部内容都在公众号内分享!话不多说,在Rocky毫无保留的分享下,让我们开始学习吧!
【目录先行】
- Stable Diffusion XL整体架构初识
- U-Net模型(Base部分)详解(包含网络结构图)
- CLIP Text Encoder模型详解(包含网络结构图)
【一】Stable Diffusion XL资源分享
- 官方项目:https://github.com/Stability-AI/generative-models
- 训练代码:https://github.com/Linaqruf/kohya-trainer
- 模型权重:https://huggingface.co/stabilityai/stable-diffusion-xl-base-0.9(只能申请访问权限)
- 模型权重百度云网盘:关注Rocky的公众号WeThinkIn,后台回复:SDXL模型,即可获得资源链接,包含Stable Diffusion XL 0.9(Base模型+Refiner模型)模型权重,Stable Diffusion XL 1.0(Base模型+Refiner模型)模型权重以及Stable Diffusion XL VAE模型权重。
- 技术报告:SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
更多Stable Diffusion XL的资源会持续发布到Rocky的知乎原文中去:https://zhuanlan.zhihu.com/p/643420260,让大家更加方便的查找最新资讯。
【二】Stable Diffusion XL整体架构初识
与Stable DiffusionV1-v2相比,Stable Diffusion XL主要做了如下的优化:
- 对Stable Diffusion原先的U-Net,VAE,CLIP Text Encoder三大件都做了改进。
- 增加一个单独的基于Latent的Refiner模型,来提升图像的精细化程度。
- 设计了很多训练Tricks,包括图像尺寸条件化策略,图像裁剪参数条件化以及多尺度训练等。
- 先发布Stable Diffusion XL 0.9测试版本,基于用户使用体验和生成图片的情况,针对性增加数据集和使用RLHF技术优化迭代推出Stable Diffusion XL 1.0正式版。
Stable Diffusion XL是一个二阶段的级联扩散模型,包括Base模型和Refiner模型。其中Base模型的主要工作和Stable Diffusion一致,具备文生图,图生图,图像inpainting等能力。在Base模型之后,级联了Refiner模型,对Base模型生成的图像Latent特征进行精细化,其本质上是在做图生图的工作。
Base模型由U-Net,VAE,CLIP Text Encoder(两个)三个模块组成,在FP16精度下Base模型大小6.94G(FP32:13.88G),其中U-Net大小5.14G,VAE模型大小167M以及两个CLIP Text Encoder一大一小分别是1.39G和246M。
Refiner模型同样由U-Net,VAE,CLIP Text Encoder(一个)三个模块组成,在FP16精度下Refiner模型大小6.08G,其中U-Net大小4.52G,VAE模型大小167M(与Base模型共用)以及CLIP Text Encoder模型大小1.39G(与Base模型共用)。
可以看到,Stable Diffusion XL无论是对整体工作流还是对不同模块(U-Net,VAE,CLIP Text Encoder)都做了大幅的改进,能够在1024×1024分辨率上从容生成图片。同时这些改进无论是对生成式模型还是判别式模型,都有非常大的迁移应用价值。
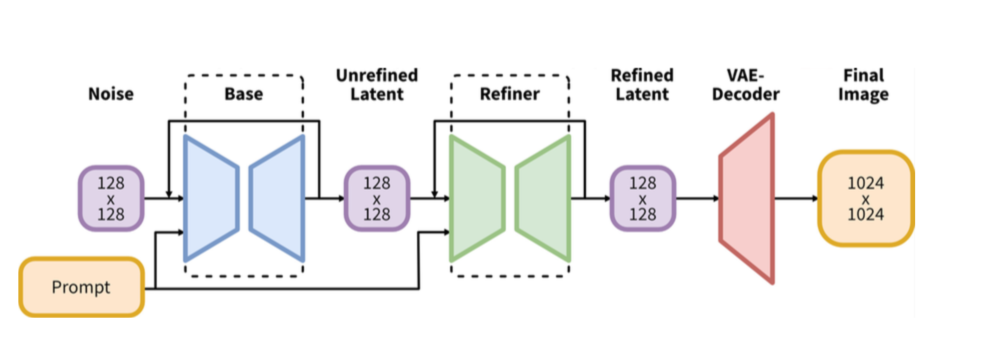 Stable Diffusion XL整体结构
Stable Diffusion XL整体结构
比起Stable Diffusion,Stable Diffusion XL的参数量增加到了101亿(Base模型35亿+Refiner模型66亿),并且先后发布了模型结构完全相同的0.9和1.0两个版本。Stable Diffusion XL 1.0使用更多训练集+RLHF来优化生成图像的色彩,对比度,光线以及阴影方面,使得生成图像的构图比0.9版本更加鲜明准确。
Rocky相信过不了多久,以Stable Diffusion XL 1.0版本为基础的AI绘画以及AI视频生态将会持续繁荣。
【三】U-Net模型(Base部分)详解(包含网络结构图)
 Stable Diffusion全系列对比图
Stable Diffusion全系列对比图
上表是Stable Diffusion XL与之前的Stable Diffusion系列的对比,从中可以看出,Stable DiffusionV1.4/1.5的U-Net参数量只有860M,就算是Stable DiffusionV2.0/2.1,其参数量也不过865M。但等到Stable Diffusion XL,U-Net模型(Base部分)参数量就增加到2.6B,参数量增加幅度达到了3倍左右。
其中增加的Spatial Transformer Blocks(Self Attention + Cross Attention)数量是新增参数量的主要部分,Rocky在上表中已经用红色框圈出。U-Net的Encoder和Decoder结构也从原来的4stage改成3stage([1,1,1,1] -> [0,2,10]),并且比起Stable DiffusionV1/2,Stable Diffusion XL在第一个stage中不再使用Spatial Transformer Blocks,而在第二和第三个stage中大量增加了Spatial Transformer Blocks(分别是2和10),大大增强了模型的学习和表达能力。
在第一个stage不使用SpatialTransformer Blocks(减少显存和计算量),并且再第二和第三个stage这两个维度较小的feature map上使用数量较多的Spatial Transformer Blocks,能在提升模型整体性能的同时,优化计算效率。在参数保持一致的情况下,Stable Diffusion XL生成图片的耗时只比Stable Diffusion多了20%-30%之间,这个拥有2.6B参数量的模型已经足够伟大。
下图是Rocky梳理的Stable Diffusion XL Base U-Net的完整结构图,大家可以感受一下其魅力,看着这个完整结构图学习Stable Diffusion XL Base U-Net部分,相信大家脑海中的思路也会更加清晰:
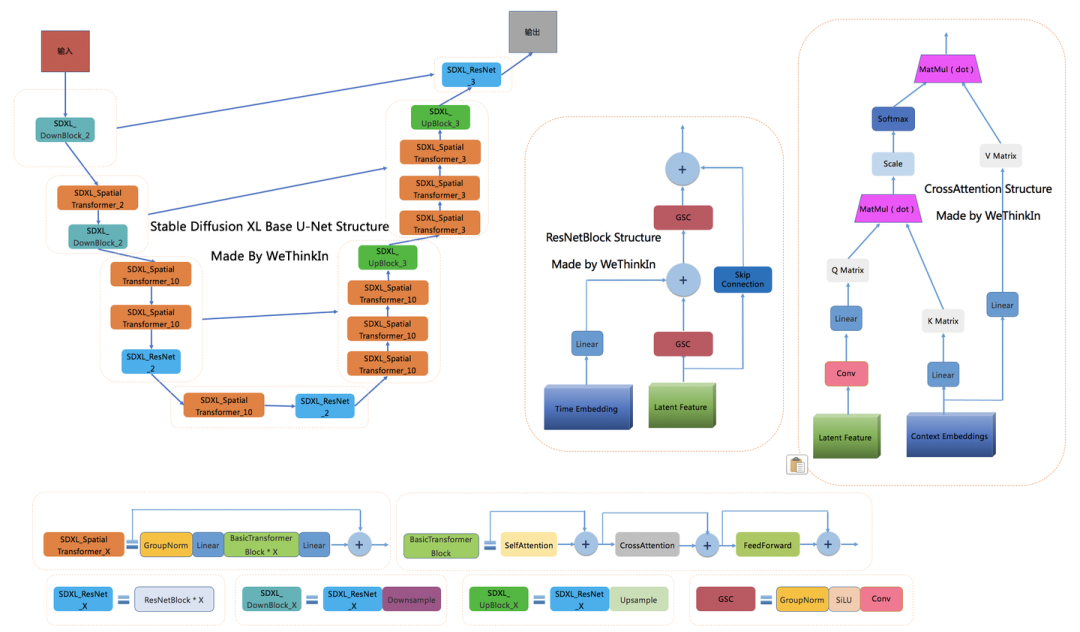 Stable Diffusion XL Base U-Net完整结构图
Stable Diffusion XL Base U-Net完整结构图
在Encoder结构中,包含了两个SDXL_DownBlock结构,三个SDXL_SpatialTransformer结构,以及一个SDXL_ResNet结构;在Decoder结构中,包含了两个SDXL_UpBlock结构,六个SDXL_SpatialTransformer结构,以及一个SDXL_ResNet结构;与此同时,Encoder和Decoder中间存在Skip Connection,进行信息的传递与融合。
可以看到BasicTransformer Blocks结构是整个框架的基石,由Self Attention,Cross Attention和FeedForward三个组件构成,并且使用了循环残差模式。
Stable Diffusion XL中的Text Condition信息由两个Text Encoder提供(OpenCLIP ViT-bigG和OpenAI CLIP ViT-L),通过Cross Attention组件嵌入,作为K Matrix和V Matrix。与此同时,图片的Latent Feature作为Q Matrix。
【四】VAE模型详解(包含网络结构图)
VAE模型(变分自编码器,Variational Auto-Encoder)是一个经典的生成式模型,其基本原理就不过多介绍了。在传统深度学习时代,GAN的风头完全盖过了VAE,但VAE简洁稳定的Encoder-Decoder架构,以及能够高效提取数据Latent特征的关键能力,让其跨过了周期,在AIGC时代重新繁荣。
Stable Diffusion XL依旧是基于Latent的扩散模型,所以VAE的Encoder和Decoder结构依旧是Stable Diffusion XL提取图像Latent特征和图像像素级重建的关键一招。
当输入是图片时,Stable Diffusion XL和Stable Diffusion一样,首先会使用VAE的Encoder结构将输入图像转换为Latent特征,然后U-Net不断对Latent特征进行优化,最后使用VAE的Decoder结构将Latent特征重建出像素级图像。除了提取Latent特征和图像的像素级重建外,VAE还可以改进生成图像中的高频细节,小物体特征和整体图像色彩。
当Stable Diffusion XL的输入是文字时,这时我们不需要VAE的Encoder结构,只需要Decoder进行图像重建。VAE的灵活运用,让Stable Diffusion系列增添了几分优雅。
Stable Diffusion XL使用了和之前Stable Diffusion系列一样的VAE结构,但在训练中选择了更大的Batch-Size(256 vs 9),并且对模型进行指数滑动平均操作(EMA,exponential moving average),EMA对模型的参数做平均,从而提高性能并增加模型鲁棒性。
下面是Rocky梳理的Stable Diffusion XL的VAE完整结构图,希望能让大家对这个在Stable DIffusion系列中未曾改变架构的模型有一个更直观的认识,在学习时也更加的得心应手:
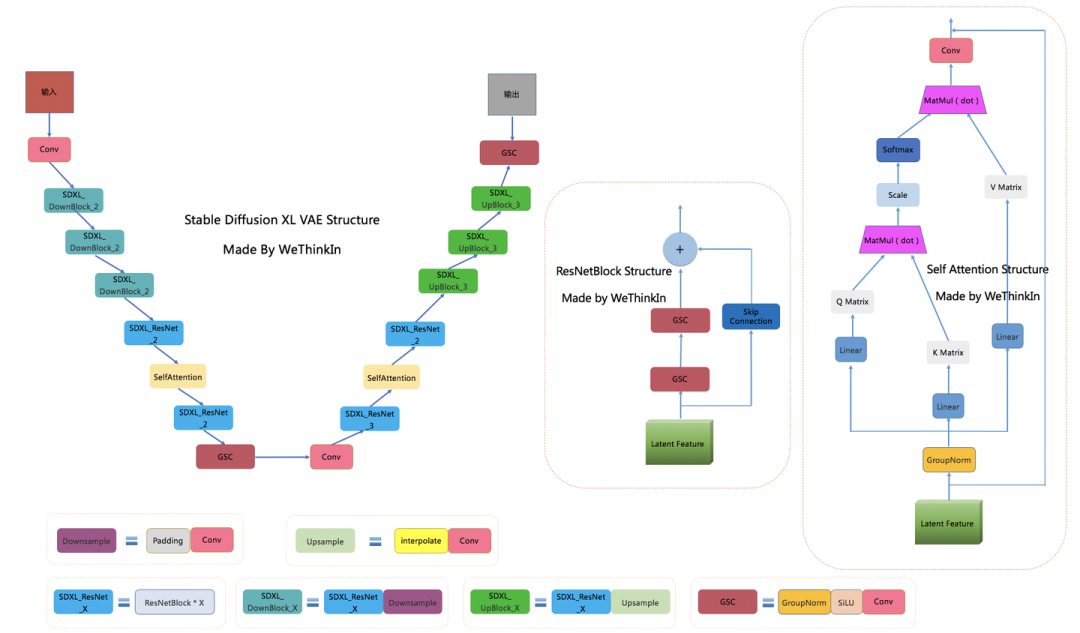 Stable Diffusion XL Base VAE完整结构图
Stable Diffusion XL Base VAE完整结构图
在损失函数方面,使用了久经考验的生成领域“交叉熵”—感知损失(perceptual loss)以及回归损失来约束VAE的训练过程。
下表是Stable Diffusion XL的VAE在COCO2017 验证集上,图像大小为256×256像素的情况下的性能。
(注:Stable Diffusion XL的VAE是从头开始训练的)
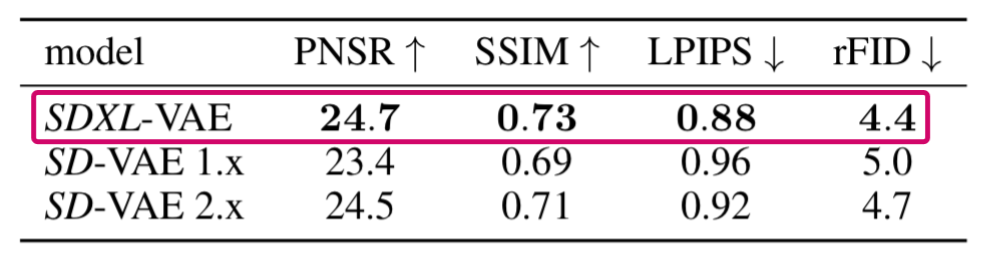 Stable Diffusion XL中优化VAE带来的性能提升
Stable Diffusion XL中优化VAE带来的性能提升
与此同时,VAE的缩放系数也产生了变化。VAE在将Latent特征送入U-Net之前,需要对Latent特征进行缩放让其标准差尽量为1,之前的Stable Diffusion系列采用的缩放系数为0.18215,由于Stable Diffusion XL的VAE进行了全面的重训练,所以缩放系数重新设置为0.13025。
注意:由于缩放系数的改变,Stable Diffusion XL VAE模型与之前的Stable Diffusion系列并不兼容。官方的Stable Diffusion XL VAE的权重已经开源:https://huggingface.co/stabilityai/sdxl-vae
在官网如果遇到网络问题或者下载速度很慢的问题,可以关注Rocky的公众号WeThinkIn,后台回复:SDXL模型,即可获得Stable Diffusion XL VAE模型权重资源链接。
【五】CLIP Text Encoder模型详解(包含网络结构图)
CLIP模型主要包含Text Encoder和Image Encoder两个模块,在Stable Diffusion XL中,和之前的Stable Diffusion系列一样,只使用Text Encoder模块从文本信息中提取Text Embeddings。
不过Stable Diffusion XL与之前的系列相比,使用了两个CLIP Text Encoder,分别是OpenCLIP ViT-bigG(1.39G)和OpenAI CLIP ViT-L(246M),从而大大增强了Stable Diffusion XL对文本的提取和理解能力。
其中OpenCLIP ViT-bigG是一个只由Transformer模块组成的模型,一共有32个CLIPEncoder模块,是一个强力的特征提取模型。其单个CLIPEncoder模块结构如下所示:
# OpenCLIP ViT-bigG中CLIPEncoder模块结构CLIPEncoderLayer( (self_attention): CLIPAttention( (k_Matric): Linear(in_features=1280, out_features=1280, bias=True) (v_Matric): Linear(in_features=1280, out_features=1280, bias=True) (q_Matric): Linear(in_features=1280, out_features=1280, bias=True) (out_proj): Linear(in_features=1280, out_features=1280, bias=True) ) (layer_norm1): LayerNorm((1280,), eps=1e-05, elementwise_affine=True) (mlp): CLIPMLP( (activation_fn): GELUActivation() (fc1): Linear(in_features=1280, out_features=5120, bias=True) (fc2): Linear(in_features=5120, out_features=1280, bias=True) ) (layer_norm2): LayerNorm((1280,), eps=1e-05, elementwise_affine=True) )OpenAI CLIP ViT-L同样是一个只由Transformer模块组成的模型,一共有12个CLIPEncoder模块,其单个CLIPEncoder模块结构如下所示:# OpenAI CLIP ViT-L中CLIPEncoder模块结构CLIPEncoderLayer( (self_attention): CLIPAttention( (k_Matric): Linear(in_features=768, out_features=768, bias=True) (v_Matric): Linear(in_features=768, out_features=768, bias=True) (q_Matric): Linear(in_features=768, out_features=768, bias=True) (out_proj): Linear(in_features=768, out_features=768, bias=True) ) (layer_norm1): LayerNorm((768,), eps=1e-05, elementwise_affine=True) (mlp): CLIPMLP( (activation_fn): QuickGELUActivation() (fc1): Linear(in_features=768, out_features=3072, bias=True) (fc2): Linear(in_features=3072, out_features=768, bias=True) ) (layer_norm2): LayerNorm((768,), eps=1e-05, elementwise_affine=True) )由上面两个结构对比可知,OpenCLIP ViT-bigG的优势在于模型结构更深,特征维度更大,特征提取能力更强,但是其两者的基本CLIPEncoder模块是一样的。与传统深度学习中的模型融合类似,Stable Diffusion XL分别提取两个Text Encoder的倒数第二层特征,并进行concat操作作为文本条件(Text Conditioning)。其中OpenCLIP ViT-bigG的特征维度为77×1280,而CLIP ViT-L的特征维度是77×768,所以输入总的特征维度是77×2048(77是最大的token数),再通过Cross Attention模块将文本信息传入Stable Diffusion XL的训练过程与推理过程中。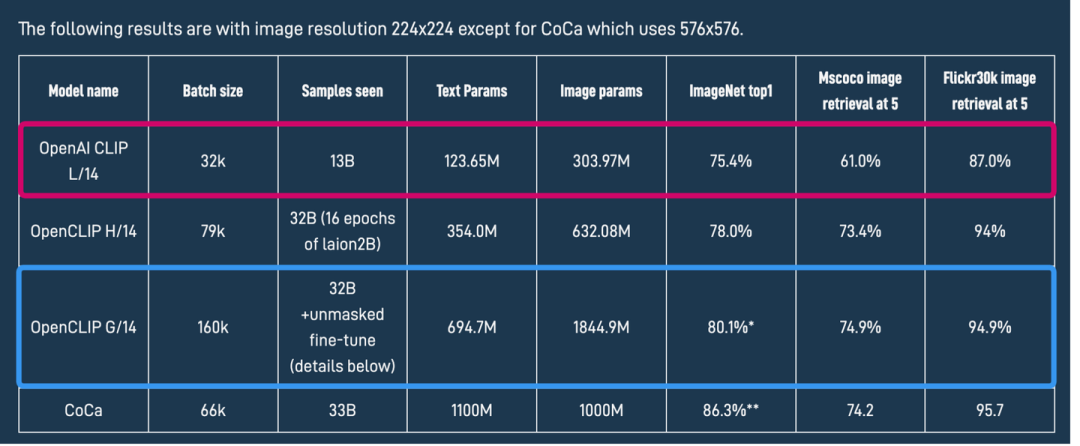 OpenCLIP ViT-bigG和OpenAI CLIP ViT-L模型性能从上图可以看到,OpenCLIP ViT-bigG和OpenAI CLIP ViT-L在ImageNet上zero-shot性能分别为80.1%和75.4%,Rocky有点疑惑的是,为什么不用CoCa或者将penAI CLIP ViT-L替换成penAI CLIP ViT-H呢。和Stable Diffusion一致的是,Stable Diffusion XL输入的最大Token数依旧是77,当输入text的Token数量超过77后,将通过Clip操作拉回77;如果Token数不足77则会padding操作得到77×2048。与此同时,Stable Diffusion XL还提取了OpenCLIP ViT-bigG的pooled text embedding,将其嵌入到time embedding中,作为辅助约束条件,但是这种辅助条件的强度是较为微弱的。
OpenCLIP ViT-bigG和OpenAI CLIP ViT-L模型性能从上图可以看到,OpenCLIP ViT-bigG和OpenAI CLIP ViT-L在ImageNet上zero-shot性能分别为80.1%和75.4%,Rocky有点疑惑的是,为什么不用CoCa或者将penAI CLIP ViT-L替换成penAI CLIP ViT-H呢。和Stable Diffusion一致的是,Stable Diffusion XL输入的最大Token数依旧是77,当输入text的Token数量超过77后,将通过Clip操作拉回77;如果Token数不足77则会padding操作得到77×2048。与此同时,Stable Diffusion XL还提取了OpenCLIP ViT-bigG的pooled text embedding,将其嵌入到time embedding中,作为辅助约束条件,但是这种辅助条件的强度是较为微弱的。
【六】Refiner模型详解(包含网络结构图)
Rocky第一次看到Stable Diffusion XL的Refiner部分时,脑海里马上联想到了DeepFloyd和StabilityAI联合开发的DeepFloyd IF。DeepFloyd IF是一种基于像素的文本到图像三重级联扩散模型,大大提升了扩散模型的图像生成能力。这次,Stable Diffusion XL终于也开始使用级联策略,在U-Net(Base)之后,级联Refiner模型,进一步提升生成图像的细节特征与整体质量。通过级联模型提升生成图片的质量,可以说这是AIGC时代里的模型融合。和传统深度学习时代的多模型融合策略一样,不管是学术界,工业界还是竞赛界,都是“行业核武”般的存在。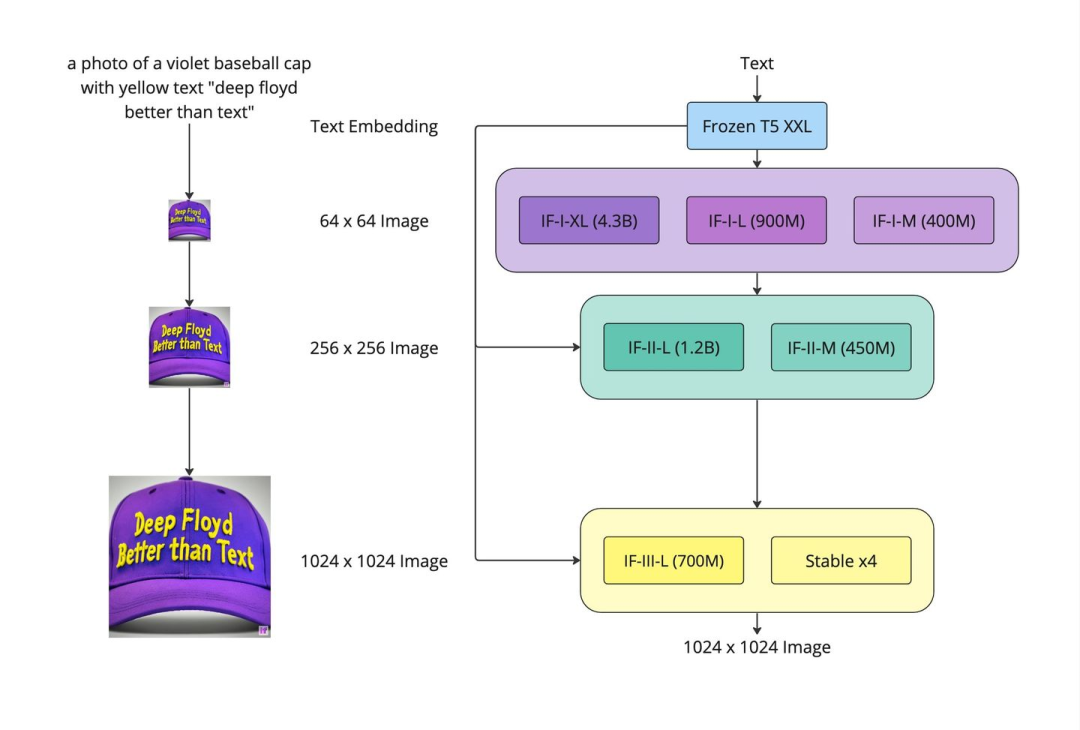 DeepFloyd IF结构图由于已经有U-Net(Base)模型生成了图像的Latent特征,所以Refiner模型的主要工作是在Latent特征进行小噪声去除和细节质量提升。
DeepFloyd IF结构图由于已经有U-Net(Base)模型生成了图像的Latent特征,所以Refiner模型的主要工作是在Latent特征进行小噪声去除和细节质量提升。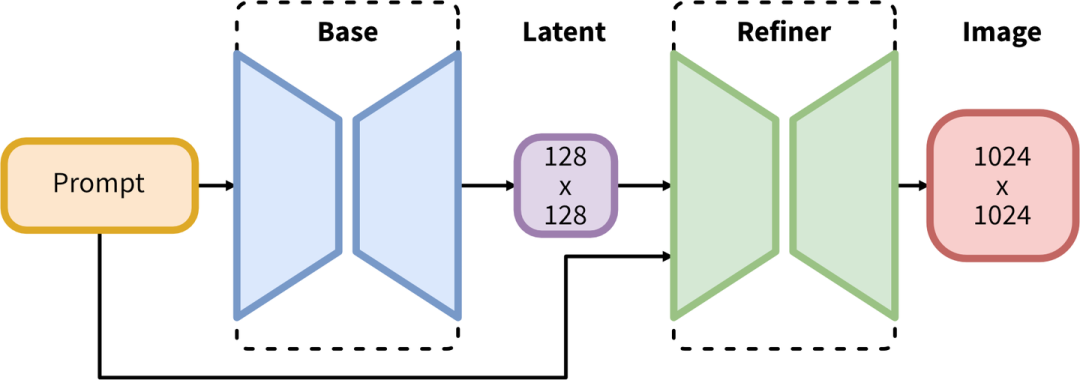 U-Net(Base)结构+Refiner结构Refiner模型和Base模型一样是基于Latent的扩散模型,也采用了Encoder-Decoder结构,和U-Net兼容同一个VAE模型,不过Refiner模型的Text Encoder只使用了OpenCLIP ViT-bigG。下图是Rocky梳理的Stable Diffusion XL Refiner模型的完整结构图,大家可以先感受一下其魅力,在学习Refiner模型时可以与Base模型中的U-Net进行对比,会有更多直观的认识:
U-Net(Base)结构+Refiner结构Refiner模型和Base模型一样是基于Latent的扩散模型,也采用了Encoder-Decoder结构,和U-Net兼容同一个VAE模型,不过Refiner模型的Text Encoder只使用了OpenCLIP ViT-bigG。下图是Rocky梳理的Stable Diffusion XL Refiner模型的完整结构图,大家可以先感受一下其魅力,在学习Refiner模型时可以与Base模型中的U-Net进行对比,会有更多直观的认识: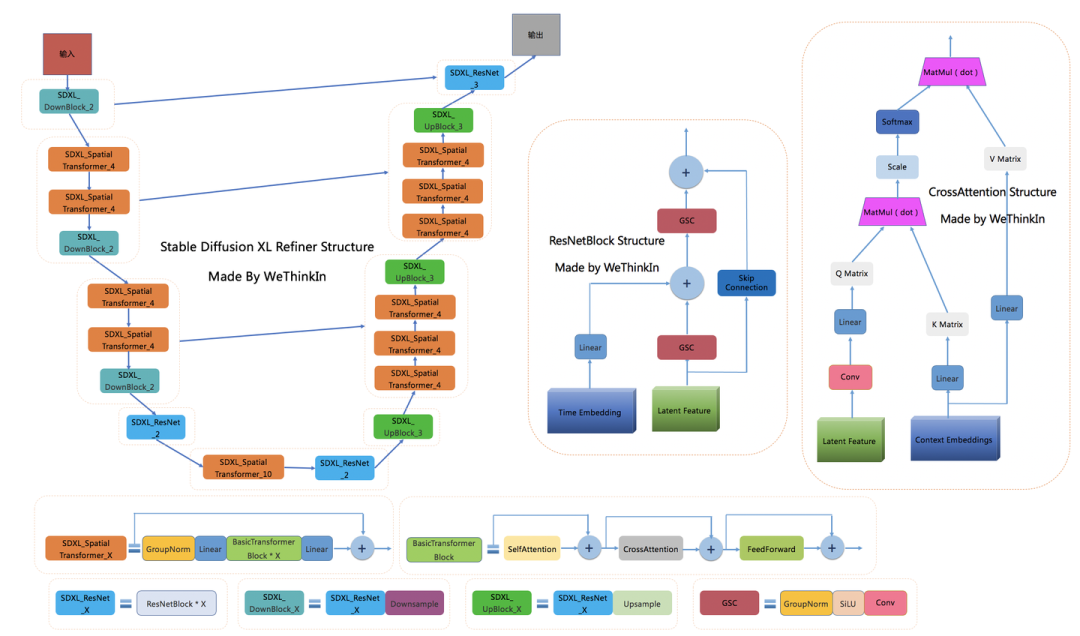 Stable Diffusion XL Refiner完整结构图在Stable Diffusion XL推理阶段,输入一个prompt,通过VAE和U-Net(Base)模型生成Latent特征,接着给这个Latent特征加一定的噪音,在此基础上,再使用Refiner模型进行去噪,以提升图像的整体质量与局部细节。
Stable Diffusion XL Refiner完整结构图在Stable Diffusion XL推理阶段,输入一个prompt,通过VAE和U-Net(Base)模型生成Latent特征,接着给这个Latent特征加一定的噪音,在此基础上,再使用Refiner模型进行去噪,以提升图像的整体质量与局部细节。 左图表示只使用Base模型,右图表示使用了Base+Refiner模型可以看到,Refiner模型主要做了图像生成图像的工作,其具备很强的迁移兼容能力,可以作为Stable Diffusion,GAN,VAE等生成式模型的级联组件,不管是对学术界,工业界还是竞赛界,无疑都是一个无疑都是一个巨大利好。
左图表示只使用Base模型,右图表示使用了Base+Refiner模型可以看到,Refiner模型主要做了图像生成图像的工作,其具备很强的迁移兼容能力,可以作为Stable Diffusion,GAN,VAE等生成式模型的级联组件,不管是对学术界,工业界还是竞赛界,无疑都是一个无疑都是一个巨大利好。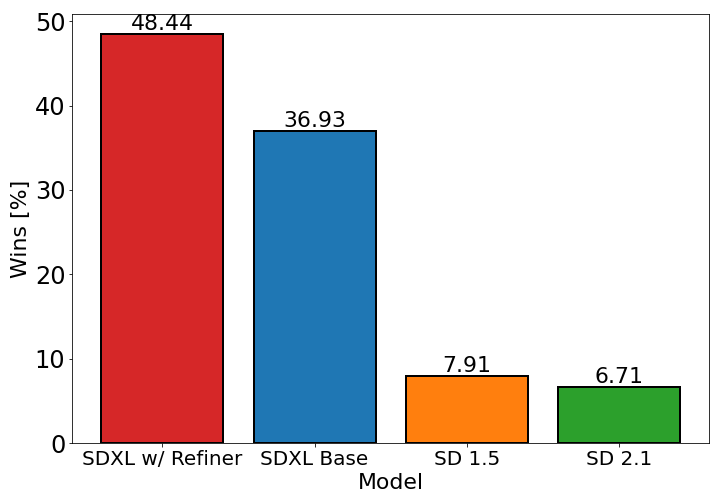 Stable Diffusion系列模型效果对比由上表可以看出,只使用U-Net(Base)模型,Stable Diffusion XL模型的效果已经大幅超过SD1.5和SD2.1,当增加Refiner模型之后,Stable Diffusion XL达到了更加优秀的图像生成效果。
Stable Diffusion系列模型效果对比由上表可以看出,只使用U-Net(Base)模型,Stable Diffusion XL模型的效果已经大幅超过SD1.5和SD2.1,当增加Refiner模型之后,Stable Diffusion XL达到了更加优秀的图像生成效果。
【七】Stable Diffusion XL训练技巧
Stable Diffusion XL在训练阶段提出了很多Tricks,包括图像尺寸条件化策略,图像裁剪参数条件化以及多尺度训练。这些Tricks都有很好的通用性和迁移性,能普惠其他的生成式模型。
图像尺寸条件化
之前在Stable Diffusion的训练过程中,主要分成两个阶段,一个是在256×256的图像尺寸上进行预训练,然后在512×512的图像尺寸上继续训练。而这两个阶段的训练过程都要对最小图像尺寸进行约束。第一阶段中,会将尺寸小于256×256的图像舍弃;同样的,在第二阶段,会将尺寸小于512×512的图像筛除。这样的约束会导致训练数据中的大量数据被丢弃,从而很可能导致模型性能和泛化性的降低。下图展示了如果将尺寸小于256×256的图像筛除,整个数据集将减少39%的数据。如果加上尺寸小于512×512的图像,未利用数据占整个数据集的百分比将更大。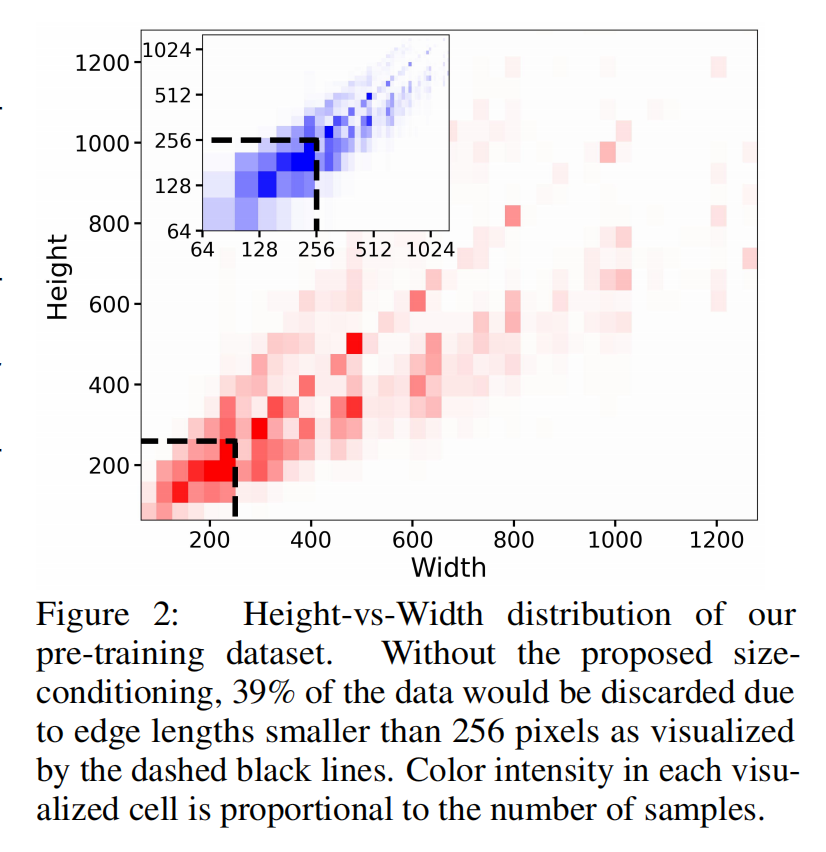 针对上述数据集利用率的问题,常规思路可以借助超分模型将尺寸过小的图像放大。但是面对对于图像尺寸过小的场景,目前的超分模型可能会在对图像超分的同时会引入一些噪声伪影,影响模型的训练,导致生成一些模糊的图像。Stable Diffusion XL为了在解决数据集利用率问题的同时不引入噪声伪影,将U-Net(Base)模型与原始图像分辨率相关联,核心思想是将输入图像的原始高度和宽度作为额外的条件嵌入U-Net模型中,表示为。height和width都使用傅里叶特征编码进行独立嵌入,然后将特征concat后加在Time Embedding上,将图像尺寸引入训练过程。这样以来,模型在训练过程中能够学习到图像的原始分辨率信息,从而在推理生成阶段更好地适应不同尺寸的图像生成,而不会产生噪声伪影的问题。如下图所示,在使用了图像尺寸条件化策略后,Base模型已经对不同图像分辨率有了“自己的判断”。当输入低分辨率条件时,生成的图像较模糊;在不断增大分辨率条件时,生成的图像质量不断提升。
针对上述数据集利用率的问题,常规思路可以借助超分模型将尺寸过小的图像放大。但是面对对于图像尺寸过小的场景,目前的超分模型可能会在对图像超分的同时会引入一些噪声伪影,影响模型的训练,导致生成一些模糊的图像。Stable Diffusion XL为了在解决数据集利用率问题的同时不引入噪声伪影,将U-Net(Base)模型与原始图像分辨率相关联,核心思想是将输入图像的原始高度和宽度作为额外的条件嵌入U-Net模型中,表示为。height和width都使用傅里叶特征编码进行独立嵌入,然后将特征concat后加在Time Embedding上,将图像尺寸引入训练过程。这样以来,模型在训练过程中能够学习到图像的原始分辨率信息,从而在推理生成阶段更好地适应不同尺寸的图像生成,而不会产生噪声伪影的问题。如下图所示,在使用了图像尺寸条件化策略后,Base模型已经对不同图像分辨率有了“自己的判断”。当输入低分辨率条件时,生成的图像较模糊;在不断增大分辨率条件时,生成的图像质量不断提升。 图像尺寸条件化策略让Base模型对图像分辨率有了“自己的判断”
图像尺寸条件化策略让Base模型对图像分辨率有了“自己的判断”
图像裁剪参数条件化
之前的Stable Diffusion系列模型,由于需要输入固定的图像尺寸用作训练,很多数据在预处理阶段会被裁剪。生成式模型中典型的预处理方式是先调整图像尺寸,使得最短边与目标尺寸匹配,然后再沿较长边对图像进行随机裁剪或者中心裁剪。虽然裁剪是一种数据增强方法,但是训练中对图像裁剪导致的图像特征丢失,可能会导致模型在图像生成阶段出现不符合训练数据分布的特征。如下图所示,一个骑士的图片做了裁剪操作后,丢失了头部和脚部特征,再将裁剪后的数据放入模型中训练,就会影响模型对骑士这个概念的认识。 “骑士”概念特征被破坏的数据下图中展示了SD1.4和SD1.5的经典失败案例,生成图像中的猫出现了头部缺失的问题,龙也出现了体征不完整的情况:
“骑士”概念特征被破坏的数据下图中展示了SD1.4和SD1.5的经典失败案例,生成图像中的猫出现了头部缺失的问题,龙也出现了体征不完整的情况: SD1.4和SD1.5的经典失败案例其实之前NovelAI就发现了这个问题,并提出了基于分桶(Ratio Bucketing)的多尺度训练策略,其主要思想是先将训练数据集按照不同的长宽比(aspect ratio)进行分桶(buckets)。在训练过程中,每次在buckets中随机选择一个bucket并从中采样Batch个数据进行训练。将数据集进行分桶可以大量较少裁剪图像的操作,并且能让模型学习多尺度的生成能力;但相对应的,预处理成本大大增加,特别是数据量级较大的情况下。并且尽管数据分桶成功解决了数据裁剪导致的负面影响,但如果能确保数据裁剪不把负面影响引入生成过程中,裁剪这种数据增强方法依旧能给模型增强泛化性能。所以Stable Diffusion XL使用了一种简单而有效的条件化方法,即图像裁剪参数条件化策略。其主要思想是在加载数据时,将左上角的裁剪坐标通过傅里叶编码并嵌入U-Net(Base)模型中,并与原始图像尺寸一起作为额外的条件嵌入U-Net模型,从而在训练过程中让模型学习到对“图像裁剪”的认识。
SD1.4和SD1.5的经典失败案例其实之前NovelAI就发现了这个问题,并提出了基于分桶(Ratio Bucketing)的多尺度训练策略,其主要思想是先将训练数据集按照不同的长宽比(aspect ratio)进行分桶(buckets)。在训练过程中,每次在buckets中随机选择一个bucket并从中采样Batch个数据进行训练。将数据集进行分桶可以大量较少裁剪图像的操作,并且能让模型学习多尺度的生成能力;但相对应的,预处理成本大大增加,特别是数据量级较大的情况下。并且尽管数据分桶成功解决了数据裁剪导致的负面影响,但如果能确保数据裁剪不把负面影响引入生成过程中,裁剪这种数据增强方法依旧能给模型增强泛化性能。所以Stable Diffusion XL使用了一种简单而有效的条件化方法,即图像裁剪参数条件化策略。其主要思想是在加载数据时,将左上角的裁剪坐标通过傅里叶编码并嵌入U-Net(Base)模型中,并与原始图像尺寸一起作为额外的条件嵌入U-Net模型,从而在训练过程中让模型学习到对“图像裁剪”的认识。 SDXL使用不同裁剪坐标获取具有裁剪效应的图像图像尺寸条件化策略和图像裁剪参数条件化策略都能以在线方式应用,也可以很好的迁移到其他生成式模型的训练中。下图详细给出了两种策略的通用使用流程:
SDXL使用不同裁剪坐标获取具有裁剪效应的图像图像尺寸条件化策略和图像裁剪参数条件化策略都能以在线方式应用,也可以很好的迁移到其他生成式模型的训练中。下图详细给出了两种策略的通用使用流程:
多尺度训练
Stable Diffusion XL采用了多尺度训练策略,这个在传统深度学习时代头牌模型YOLO系列中常用的增强模型鲁棒性与泛化性策略,终于在AIGC领域应用并固化了,并且Stable Diffusion XL在多尺度的技术上,增加了分桶策略。
Stable Diffusion XL首先在256×256和512×512的图像尺寸上分别预训练600000步和200000步(batch size = 2048),总的数据量 600000 x 2000000 x 2048 约等于16亿。
接着Stable Diffusion XL在1024×1024的图像尺寸上采用多尺度方案来进行微调,并将数据分成不同纵横比的桶(bucket),并且尽可能保持每个桶的像素数接近1024×1024,同时相邻的bucket之间height或者width一般相差64像素左右,Stable Diffusion XL的具体分桶情况如下图所示:
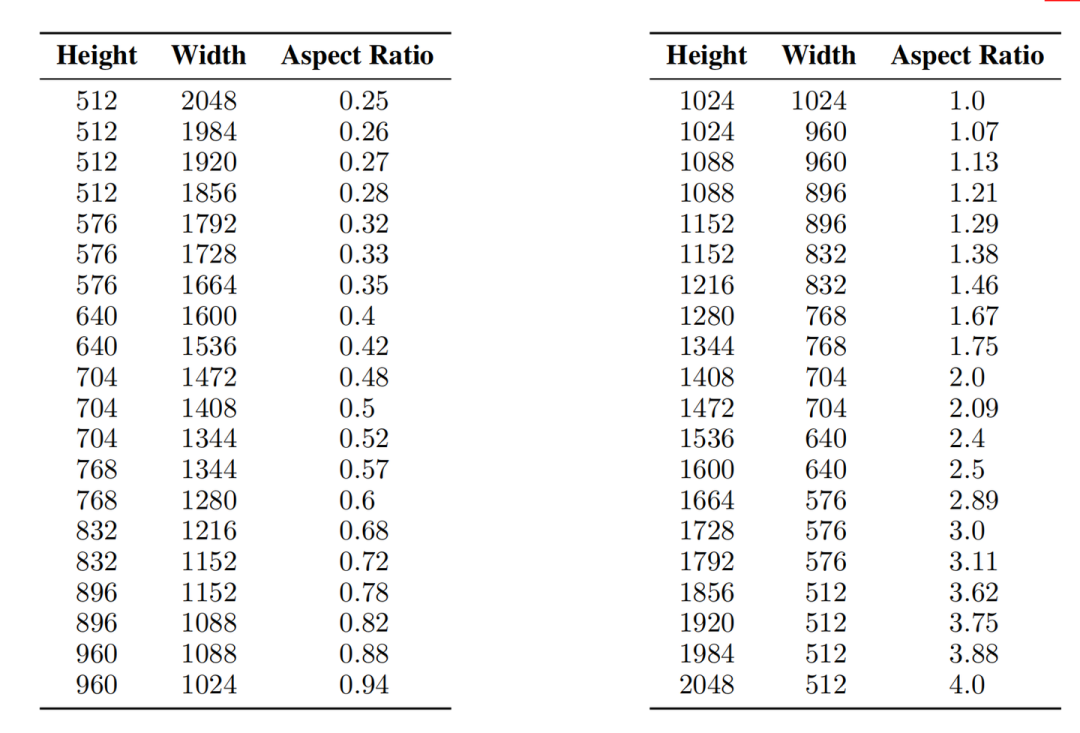 Stable Diffusion XL训练中使用的多尺度分桶训练策略其中Aspect Ratio = Height / Width,表示高宽比。在训练过程中,一个Batch从一个桶里的图像采样,并且我们在每个训练步骤中在不同的桶大小之间交替切换。除此之外,aspect ratio也会作为条件嵌入到U-Net(Base)模型中,让模型能够更好地学习到“多尺度特征”。完成了多尺度微调后,Stable Diffusion XL就可以进行不同aspect ratio的AI绘画了,不过Rocky推荐生成尺寸的base设置为1024×1024。
Stable Diffusion XL训练中使用的多尺度分桶训练策略其中Aspect Ratio = Height / Width,表示高宽比。在训练过程中,一个Batch从一个桶里的图像采样,并且我们在每个训练步骤中在不同的桶大小之间交替切换。除此之外,aspect ratio也会作为条件嵌入到U-Net(Base)模型中,让模型能够更好地学习到“多尺度特征”。完成了多尺度微调后,Stable Diffusion XL就可以进行不同aspect ratio的AI绘画了,不过Rocky推荐生成尺寸的base设置为1024×1024。
免责声明
本文内容(图片、文章)翻译/转载自国内外资讯/自媒体平台。文中内容不代表本站立场,如有侵权或其它,请联系 admin@eiefun.com,我们会第一时间配合删除。